Une approche technique pour exploiter Semantic Find afin de résoudre le problème complexe du “fuzzy matching”

Dans la partie 1 de cet article, j’ai décrit en quoi la fonction Recherche sémantique (Semantic Find) de FileMaker diffère de la recherche classique, ce qu’est la correspondance d’entités (Entity Matching) (et pourquoi elle est importante pour les utilisateurs de FileMaker) et comment la Recherche sémantique peut faciliter les tâches de déduplication. Ici, dans la partie 2, je vais aborder en détail une approche de correspondance d’entités dans FileMaker en utilisant la Recherche sémantique pour effectuer un fuzzy matching. Je ne traiterai que brièvement la mise en place de la Recherche sémantique dans une solution FileMaker (de nombreux autres articles couvrent déjà ce sujet en profondeur), mais je présenterai les choix de conception spécifiques à la correspondance d’entités.
Qu’est-ce que la correspondance d’entités ?
La correspondance d’entités consiste à déterminer si deux enregistrements se rapportent à la même entité réelle. C’est indispensable dans de nombreux contextes et crucial pour la déduplication des données. C’est aussi un problème récurrent et difficile dans les systèmes FileMaker que je côtoie au quotidien.
Le problème de base consiste à pouvoir comparer deux (ou plusieurs) enregistrements et à déterminer, de manière programmatique, s’ils font réellement référence à la même chose. Est-ce que « Hanna C Beuler » est la même personne que « Hannah Bueler » ?
Enregistrement 1 : Hanna C Bueler, née le 03/12/1990
Enregistrement 2 : Hannah Beuler, née le 12/03/1990
Dans FileMaker, en utilisant la recherche classique « correspondance exacte », il serait difficile de repérer ces deux enregistrements pour les comparer (leurs orthographes et dates de naissance diffèrent), sans parler de déterminer s’ils correspondent. Un utilisateur humain verrait rapidement qu’il s’agit probablement de la même personne, mais une recherche FileMaker simple ne le peut pas. C’est là que la Recherche sémantique entre en jeu.
Rechercher une correspondance
Le processus habituel de recherche de doublons consiste à interroger plusieurs champs (ou un champ calculé concaténé) pour une correspondance exacte :
Enter Find Mode [ Pause: Off ]
Set Field [ Person::FirstName ; “Hanna” ]
Set Field [ Person::LastName ; “Bueler” ]
Set Field [ Person::DOB ; “3/12/1990” ]
Perform Find [ ]Cela va sans dire : si vous trouvez ce que vous cherchez par ce type de recherche standard, vous n’avez pas besoin de la recherche sémantique ! Vous avez trouvé une correspondance et pouvez passer à la suite. Cependant, si votre recherche initiale ne donne aucun résultat exact, il est temps d’utiliser la recherche sémantique pour repérer une correspondance proche (mais non exacte). La recherche sémantique change la donne pour retrouver des enregistrements difficiles à apparier une fois la recherche « exacte » épuisée.
Configurer FileMaker pour la correspondance d’entités
Pour effectuer une correspondance d’entités à l’aide de la Recherche sémantique dans FileMaker, nous devons d’abord créer des vector embeddings pour nos données d’appariement.
Embeddings
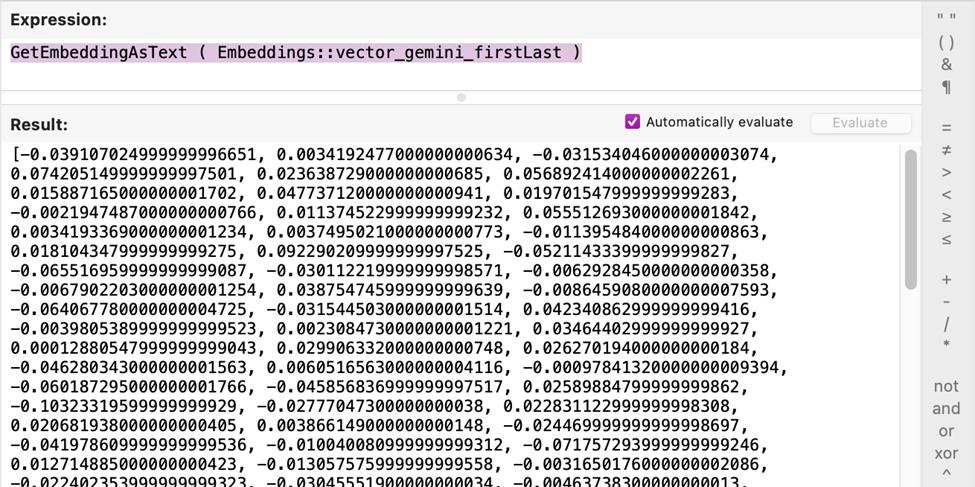
Un embedding vectoriel est une représentation numérique de données qui en capture le sens sémantique. Nous stockons les embeddings de nos données de recherche dans un champ conteneur. La Recherche sémantique de FileMaker compare ensuite ces vecteurs à votre requête et renvoie un score de similarité. La première étape consiste donc à décider quelles données vous souhaitez apparier et à ajouter des champs conteneurs pour stocker leurs embeddings.
Bien que les embeddings puissent être stockés dans la table de recherche elle-même, je préfère les conserver dans une table distincte en relation un-à-un avec leur table de données. Avec FileMaker 22 et son support intégré d’OpenAI, Anthropic ou Cohere, c’est aussi simple qu’utiliser l’étape de script « Insérer un embedding dans l’ensemble trouvé » et choisir les champs à vectoriser :
Insert Embedding in Found Set [ Account Name: “My_Semantic_Find” ; Embedding Model: $$loaded_model ; Source Field: Person::ConcatenatedFirstLastDOB ; Target Field: EmbeddingTable::VectorizedFirstLastDOB ; Replace target contents ]J’ai choisi d’utiliser le modèle d’embedding Gemini de Google au lieu de l’un des fournisseurs intégrés, car :
- J’aime les outils Google
- Les performances et la précision du modèle sont excellentes
- Les embeddings font la moitié de la taille de ceux d’OpenAI (6k contre 12k)
- Leur modèle d’embedding est gratuit
Utiliser Gemini demande un peu plus de travail, car il faut faire un appel REST avec l’étape « Insérer à partir de l’URL », analyser les données du vecteur obtenu et stocker l’embedding dans un champ conteneur sous forme de fichier binaire (en utilisant la fonction « GetEmbeddingAsFile »), mais ce n’est pas difficile si vous êtes familier avec les appels API dans FileMaker.
Une fois nos embeddings ajoutés, nous pouvons commencer à interroger notre table de données avec la Recherche sémantique.
Considérations pour les embeddings
La correspondance d’entités est différente d’une recherche sémantique ordinaire, car nous ne cherchons pas tant la similarité de sens qu’une simple similarité. Nous voulons apparier « Hannah Beuler » avec « Hanna C Bueler », pas avec [plusieurs paragraphes sur la vie de Hanna C Bueler]. Ainsi, il suffit de créer des embeddings d’une sélection de champs utilisés pour l’appariement. Et comme ces champs sont généralement courts, le nombre de tokens reste faible.
Pour choisir quoi vectoriser pour la correspondance d’entités, la méthode que j’ai utilisée avec succès consiste à créer un champ calculé de courte phrase d’appariement qui, si identique à votre requête, représenterait une correspondance parfaite. Par exemple, si vous cherchez une personne, vous pouvez créer un champ calculé composé du Prénom, Nom, Date de naissance et Numéro de téléphone. Si vous cherchez une organisation, vous pouvez utiliser Nom de l’organisation, Adresse et Numéro de téléphone. Pour un produit de catalogue, vous pouvez utiliser Description de l’article et Taille. Voici quelques directives de base :
- Choisir des champs discrets qui peuvent varier légèrement par rapport à une correspondance exacte, mais qui identifient bien une entité spécifique.
- Utiliser de petits champs texte plutôt que de longues chaînes de texte pour obtenir un pourcentage de correspondance plus élevé.
- La Recherche sémantique est sensible à la casse ; pour plus de précision, éliminez les différences de casse lorsque cela n’a pas d’importance.
Fuzzy Matching : étape par étape
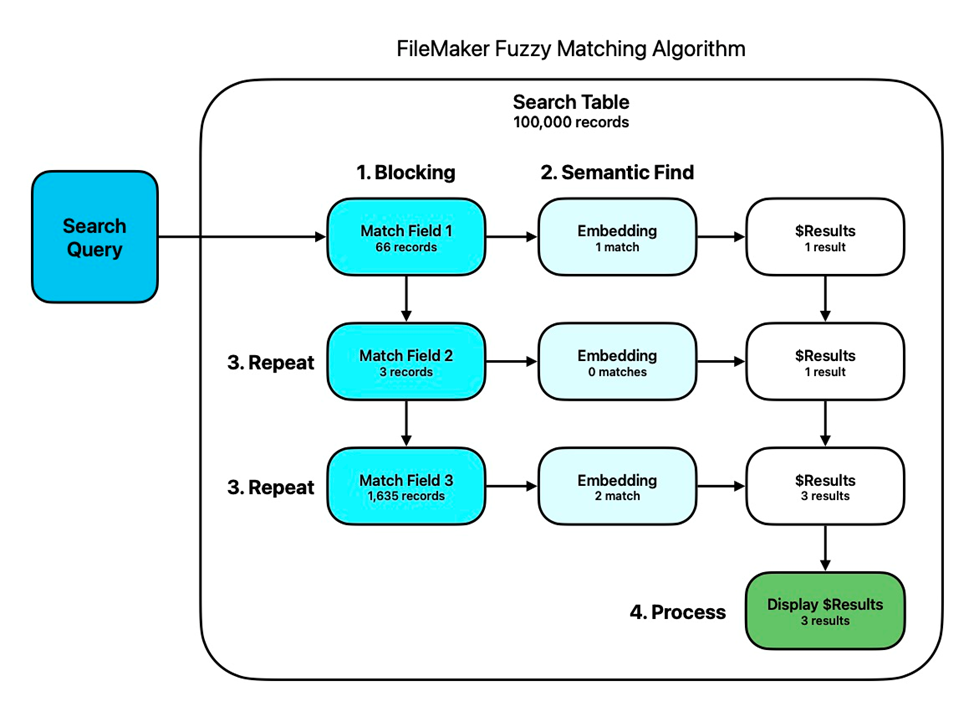
Une fois vos champs d’appariement choisis et leurs embeddings créés, le processus de correspondance d’entités avec la Recherche sémantique se déroule ainsi :
- Blocking – Effectuer une recherche FileMaker standard sur un seul champ pour créer un sous-ensemble d’enregistrements plus susceptibles de contenir la correspondance recherchée.
- Recherche sémantique – Effectuer la Recherche sémantique sur ce sous-ensemble d’enregistrements, en collectant les correspondances dans une variable.
- Répétition – Boucler sur les étapes 1 et 2 plusieurs fois, en changeant de champ de blocage à chaque fois, et ajouter les nouveaux résultats (en évitant les doublons).
- Traitement – Exploiter les résultats comme vous le souhaitez.
Ce processus doit produire un ou plusieurs enregistrements correspondant exactement à une partie de la requête, mais de façon floue au reste. Idéalement, l’un d’eux aura un score suffisamment élevé pour que vous puissiez le considérer comme une correspondance.
Étape 1 – Blocage
Comme la performance de la Recherche sémantique peut être lente sur de grands ensembles de données, il est généralement nécessaire de réduire la taille de l’ensemble trouvé initial. C’est ce qu’on appelle le blocking et cela vise à réduire le nombre d’enregistrements à rechercher pour trouver ce que nous cherchons.
Le blocage est la première étape de la résolution d’entités. Il consiste à regrouper les enregistrements similaires en fonction de certains attributs. Ce faisant, le processus limite sa recherche aux comparaisons à l’intérieur de chaque bloc, plutôt que d’examiner toutes les paires possibles dans l’ensemble de données.
Cela réduit considérablement le nombre de comparaisons et accélère le processus de résolution d’entités. Comme de nombreuses comparaisons sont ainsi écartées, il est toutefois possible que certains vrais doublons soient manqués. C’est pourquoi le blocage doit trouver un bon équilibre entre efficacité et précision. ( Tomonori Masui, Sept 21, 2023 – Towards Data Science ) Il faut en effet beaucoup moins de temps pour effectuer une recherche sémantique sur 1 000 enregistrements que sur 100 000 enregistrements, ce qui rend ce processus essentiel.
Il faut beaucoup moins de temps pour effectuer une Recherche sémantique sur 1 000 enregistrements que sur 100 000, donc ce processus est essentiel.
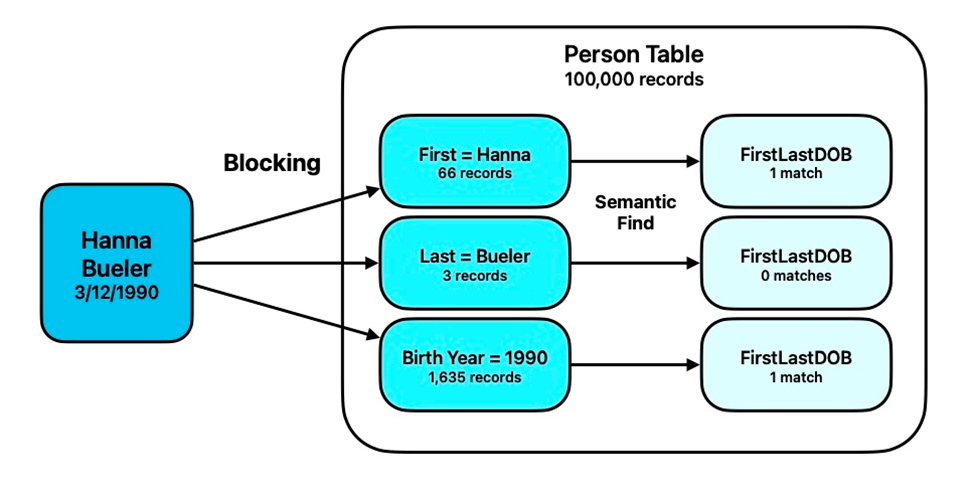
Commencez par identifier une méthode pour éliminer le plus grand nombre d’enregistrements de votre ensemble trouvé initial. Le plus grand compromis entre efficacité et précision peut se situer dans la façon dont vous décidez de le faire. L’idée est d’obtenir un ensemble plus petit d’enregistrements ayant une plus grande probabilité de contenir la correspondance recherchée, dans lequel nous pourrons rechercher plus loin avec la Recherche sémantique. Exemples :
- Si vous recherchez dans une table Contacts et que vous savez que le contact recherché est dans la catégorie « Facturation », commencez par réduire votre ensemble trouvé à ces enregistrements.
- Si vous essayez de trouver un doublon pour « Hanna Beuler », commencez par réduire votre ensemble trouvé à tous les enregistrements dont le Prénom est « Hanna » ; la deuxième fois, recherchez tous les enregistrements dont le Nom est « Bueler » ; une troisième passe pourrait limiter aux personnes nées en 1990.
- Dans une table Organisations, vous pourriez limiter votre premier blocage par Ville, le deuxième par Code postal et le troisième par Type d’organisation.
Étape 2 – Effectuer la Recherche sémantique sur chaque bloc
Dans chaque ensemble trouvé issu d’un blocage, effectuez la Recherche sémantique sur votre champ d’embedding. Comme vous voulez comparer votre texte de départ avec le champ d’embedding, vous devez créer un embedding à la volée de votre texte de départ. Dans notre exemple « Hanna Beuler », les embeddings dans notre grande table de 100k Personnes sont créés à partir d’un champ concaténé composé du Prénom, Initiale du milieu, Nom et Date de naissance (au format ISO) comme ceci :
Hannah C Bueler 1990-12-03
Quand nous lançons notre recherche sémantique, nous devons prendre notre chaîne de recherche « Hanna Beuler, 3/12/1990 » et créer un embedding à partir de celle-ci en utilisant exactement le même format que celui de nos champs d’embedding, pour que cela donne :
Hanna Beuler 1990-03-12
L’embedding doit aussi être créé avec le même modèle que celui utilisé pour créer tous les embeddings dans votre table de recherche. Utilisez l’étape de script « Insérer embedding » sur cette seule chaîne de recherche et, au lieu de la stocker dans un champ conteneur d’une table, stockez cet embedding dans un champ conteneur global :
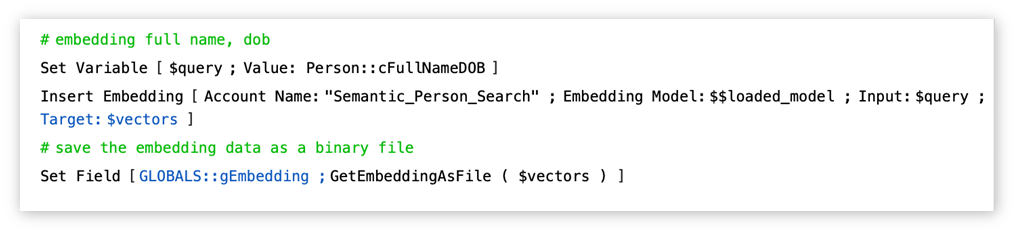
…et utilisez ensuite ce champ global dans la Recherche sémantique comme paramètre « Vecteur » dans l’étape de script « Exécuter la recherche sémantique » :

Paramètres recommandés pour l’étape « Exécuter la recherche sémantique » :
Query by: Vector Data
Vector: [your global embedding field] //this is the search query
Record Set: Current Found Set //this is the set of records reduced by blocking
Target field: [your embedding field] //this is where your embeddings are stored
Return count: 10 //this may vary, but keep it relatively small
Cosine similarity condition: greater than
Cosine similarity value: .85 //my tests indicate that < 85% match is not very good
Save result: $result_variable //store results in a variableÉtape 3 – Répéter le processus de blocage
Maintenant que vous avez recherché sur un champ et effectué une Recherche sémantique dans cet ensemble trouvé sur le champ vectorisé et stocké les résultats dans une variable, répétez ce processus avec un nouveau champ d’appariement. Chaque fois que nous obtenons un ensemble trouvé réduit, nous effectuons une Recherche sémantique sur cet ensemble trouvé, en utilisant le même champ global d’embedding, et nous ajoutons les nouveaux résultats à notre variable $Results (en sautant les doublons).
Nous espérons qu’au cours de ces multiples recherches (aucune ne donnant à elle seule une correspondance forte), au moins l’un des ensembles trouvés contiendra une correspondance partielle avec l’enregistrement réel « Hannah C Bueler » que nous pourrons alors apparier à l’aide de la Recherche sémantique.
Si, après ce processus, nous n’avons toujours trouvé aucune correspondance proche, nous pouvons supposer soit a) que les doublons éventuels sont peut-être trop différents pour être facilement localisés, soit b) qu’il n’y a pas de doublons à trouver.
Étape 4 – Traiter les résultats de la Recherche sémantique
À ce stade, le processus doit nous laisser avec une variable JSON contenant un tableau de correspondances qui ressemble à ceci :
[
{"recordId":"99920","similarity":0.988967784539129},
{"recordId":"87405","similarity":0.829515648500795},
{"recordId":"49850","similarity":0.802658597565103},
{"recordId":"45721","similarity":0.817432345089549}
]Ce que vous choisissez de faire de ces résultats dépendra de votre cas d’utilisation spécifique. Puisque le but de la correspondance d’entités est de rechercher des doublons, leur traitement dépendra de votre logique métier. Le score de similarité cosinus vous indique à quel point les embeddings vectoriels étaient proches et donne une bonne indication d’une correspondance probable. Alors que tous les grands modèles de langage ont des variations, parmi ceux que j’ai testés (
- Afficher les correspondances à l’utilisateur dans une liste virtuelle.
- Créer une table de jointure reliant l’enregistrement de recherche initial à ses enregistrements correspondants dans une table séparée.
- Fusionner immédiatement les doublons ayant un score de similarité suffisant.
- Créer automatiquement un nouvel enregistrement si aucun score élevé n’est renvoyé.
- Marquer les enregistrements pour un examen manuel ultérieur.
Ce que j’ai fait (preuve de concept)
J’ai construit et testé un proof-of-concept de correspondance d’entités dans Claris FileMaker 22 pour trouver des Personnes dans une base de ~102 000 enregistrements. L’idée est basée sur un cas d’utilisation dans lequel des résultats de laboratoire entrants, contenant des informations sur des patients, doivent être appariés à une grande table d’enregistrements Personne pour une enquête de santé publique.
Environnement
Le fichier de test contient quatre tables :
- Patient – contient nos données d’entrée
- Personne – l’ensemble complet des enregistrements Personne à interroger
- Embeddings – contient les embeddings vectoriels des enregistrements Personne
- SearchJoin – une table de jointure pour relier les résultats de notre recherche à l’enregistrement d’entrée
Il y a aussi quelques champs globaux dans leur propre table, mais ils pourraient se trouver n’importe où.
Le fichier est hébergé sur un serveur FM version 22.0.1, récemment optimisé spécifiquement pour la Recherche sémantique sur le serveur. J’ai essayé cela sur des versions de serveur antérieures et les performances n’étaient pas bonnes, il est donc recommandé d’utiliser la dernière version de FileMaker Server pour profiter des améliorations récentes de la Recherche sémantique. Déporter vos recherches sur le serveur à l’aide de PSoS est fortement recommandé. Une recherche typique utilisant les techniques décrites ici prend généralement quelques secondes, mais avec divers ajustements du blocage et des conditions du serveur, cela peut varier.
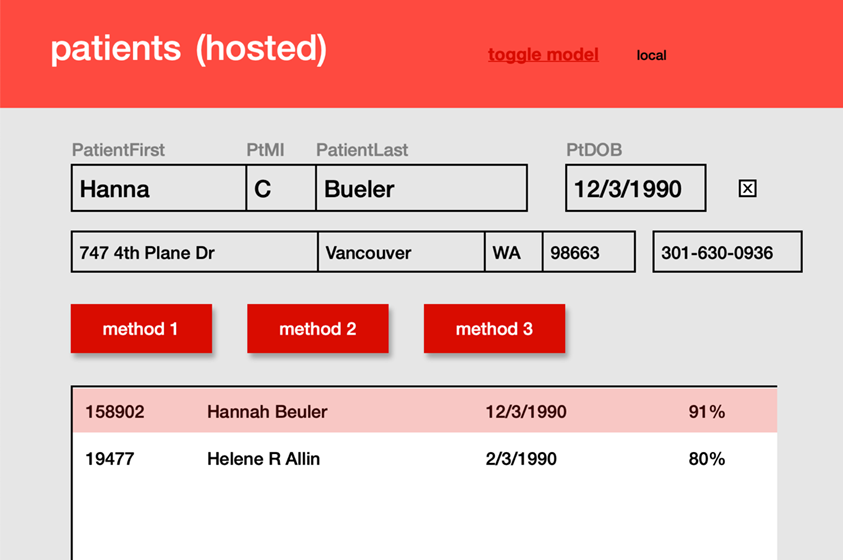
En partant d’un seul enregistrement Personne comme « entrée » (l’enregistrement Patient), je recherche dans la table Personne une correspondance probable. Je commence par bloquer sur quatre champs différents (Prénom, Nom, Date de naissance et Numéro de téléphone), et j’exécute la Recherche sémantique sur chaque sous-ensemble réduit en utilisant un embedding du Nom complet et de la Date de naissance. Les résultats sont très bons et peuvent même identifier des correspondances probables lorsque les trois points de données (Prénom, Nom, Date de naissance) diffèrent légèrement ! Avec de légères variations sur un ou deux de ces points, les performances sont remarquables.
Quand une liste de correspondances est renvoyée avec une similarité supérieure à 85 %, je crée des enregistrements dans une table de jointure qui affiche les enregistrements correspondants et leurs scores pour l’utilisateur. À ce stade, ils peuvent choisir de fusionner les deux enregistrements ou d’en supprimer un et de conserver l’autre.
Conclusion
Les fonctionnalités Recherche sémantique de FileMaker 22, utilisées comme décrit ici, peuvent donner d’excellents résultats lorsqu’elles sont utilisées pour la correspondance d’entités comme première étape d’un processus de déduplication des données. Cela vous donne, je l’espère, un point de départ pour déployer votre propre module de « Fuzzy Matching » dans vos systèmes FileMaker pour résoudre des problèmes de correspondance d’entités complexes. Cela peut vraiment changer la donne.