A technical approach for leveraging Semantic Find to solve the difficult problem of fuzzy matching

In part 1 of this article, I described how FileMaker’s Semantic Find differs from its regular find, what Entity Matching is (and why it’s important for FileMaker users), and how Semantic Find can make deduplication tasks easier. Here in part 2, I’ll cover the specifics of an entity matching approach in FileMaker using Semantic Find to perform fuzzy matching. I’ll only briefly touch on how to set up Semantic Find in a FileMaker solution, since there are plenty of other articles covering this topic in detail, but I will go over the design choices specific to entity matching.
What Is Entity Matching?
There’s a great overview of Entity Matching at the link above, but if you aren’t familiar with it (and you haven’t read part 1 of this article), it’s the process of determining if two records refer to the same real-world entity. It’s required in a wide variety of contexts, and is crucial for the deduplication of data. It has also been a continual and vexing problem in the FileMaker systems I work with daily.
The basic problem is to be able to compare two (or more) records and figure out, programmatically, whether they’re actually referring to the same thing. Is “Hanna C Beuler” the same person as “Hannah Bueler”?
Record 1: Hanna C Bueler, born on 03/12/1990
Record 2: Hannah Beuler, born on 12/03/1990
In FileMaker, using the normal “exact match” find, it would be difficult to even locate these two records to compare to each other (since their spelling and dates of birth are different), let alone determine if they’re a match. A human user could see pretty quickly that these are likely the same person, but a simple FileMaker search can’t do that. This is where Semantic Find comes in.
Looking for a Match
The usual process of looking for duplicates would be to search multiple fields (or some kind of concatenated calculation field) for an exact match:
Enter Find Mode [ Pause: Off ]
Set Field [ Person::FirstName ; “Hanna” ]
Set Field [ Person::LastName ; “Bueler” ]
Set Field [ Person::DOB ; “3/12/1990” ]
Perform Find [ ]Perhaps this goes without saying, but if you find what you’re looking for using this type of standard search, then you don’t need to do anything with semantic find! You’ve found a match, and you can move on. However, if your initial search turns up no exact matches, it’s time to try semantic find to locate a close (but not exact) match. Semantic find is a game-changer for finding tough-to-match records once you’ve exhausted the simple “exact match” find.
Setting up FileMaker for Entity Matching
In order to perform entity matching using Semantic Find in FileMaker, we first need to create vector embeddings for our match data.
Embeddings
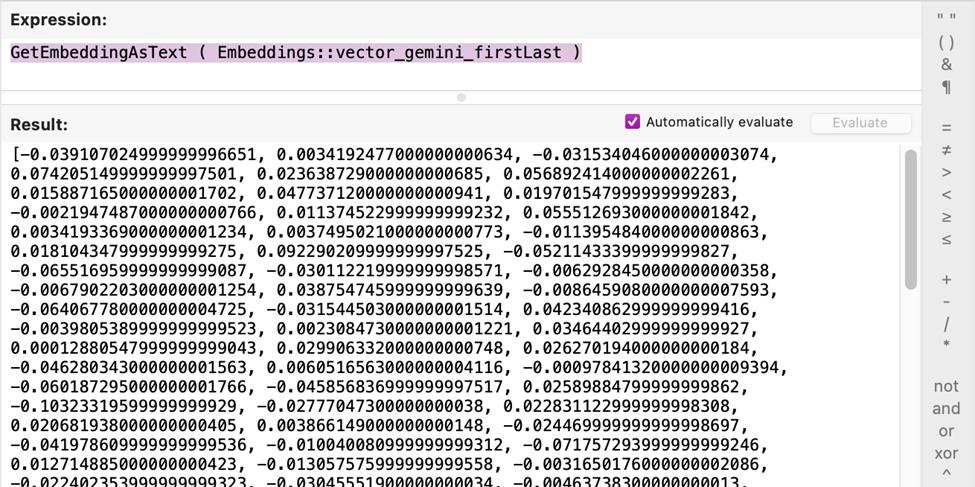
A vector embedding is a numerical representation of data that captures its semantic meaning. We store embeddings of our search data in a container field. FileMaker’s Semantic Find then compares these vectors with your search query, returning a similarity score. So, the first thing to do is decide what data you’d like to match against and add container fields to store their embeddings.
While embeddings can be stored in the search table itself, I prefer to store them in a separate table in a one-to-one relationship with their data table. Using FileMaker 22’s built-in support for either OpenAI, Anthropic, or Cohere, this is as easy as using the ‘Insert Embedding in Found Set’ script step and choosing the fields you’d like to create embeddings for:
Insert Embedding in Found Set [ Account Name: “My_Semantic_Find” ; Embedding Model: $$loaded_model ; Source Field: Person::ConcatenatedFirstLastDOB ; Target Field: EmbeddingTable::VectorizedFirstLastDOB ; Replace target contents ]I opted to use Google’s Gemini embedding model instead of one of the built in model providers, since
- I like Google’s tools
- The model’s performance and accuracy are excellent
- The embeddings are half the size of OpenAI’s (6k vs. 12k), and
- Their embedding model is free
Using Gemini requires a bit more work, since it requires making a REST call with the ‘Insert from URL’ script step, parsing the resulting vector data, and storing the embedding in a container field as a binary file (using the ‘GetEmbeddingAsFile’ function), but it’s not too difficult if you’re familiar with making API calls in FileMaker:
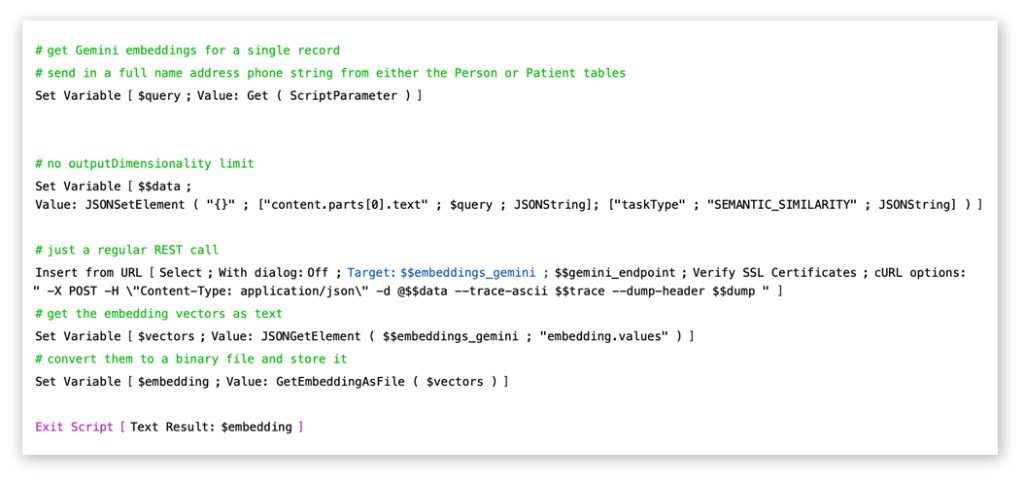
Once we’ve added our embeddings, we can begin to search against our data table using Semantic Find.
Embedding considerations
Entity matching is different from an ordinary semantic find, since we’re not so much looking for similarity in meaning as we are looking for just plain similarity. We want to match “Hannah Beuler” with “Hanna C Bueler”, not with [several paragraphs about the life of Hanna C Bueler]. This being the case, we only need to create vector embeddings of a selection of fields used for matching. And since the fields we select will typically be pretty small (as opposed to large blocks of text), the token count will remain small as well.
So how do we pick what to vectorize for entity matching? There are probably any number of ways to approach this, but the method I’ve used with success is to create a calculated field of a short match phrase that, if identical to your query, would represent a perfect match. So, if you’re searching for a person, you might create a calculation field consisting of FirstName, LastName, DateOfBirth, and PhoneNumber. If you’re searching for an organization, you might use OrganizationName, Address, and PhoneNumber. For a catalog product, you might use ItemDescription and Size. Here are some basic guidelines:
- Choose discrete fields that may vary slightly from an exact match, but that are also good identifiers of a specific entity.
- Use small text fields instead of large text strings to get higher match percentage. This is different from semantic find where we’re looking for meaning — in which case, we want to see how much our query matches all of the text. For entity matching, multiple short text strings that all have a high match will be more effective.
- Semantic Find is case sensitive, so for better accuracy, eliminate case differences where case doesn’t matter (‘FIRSTNAME LASTNAME’ should always be 100% match with ‘Firstname Lastname’, but an acronym like ‘USIC’ shouldn’t be a good match for ‘Music’ ).
Fuzzy Matching: Step by Step
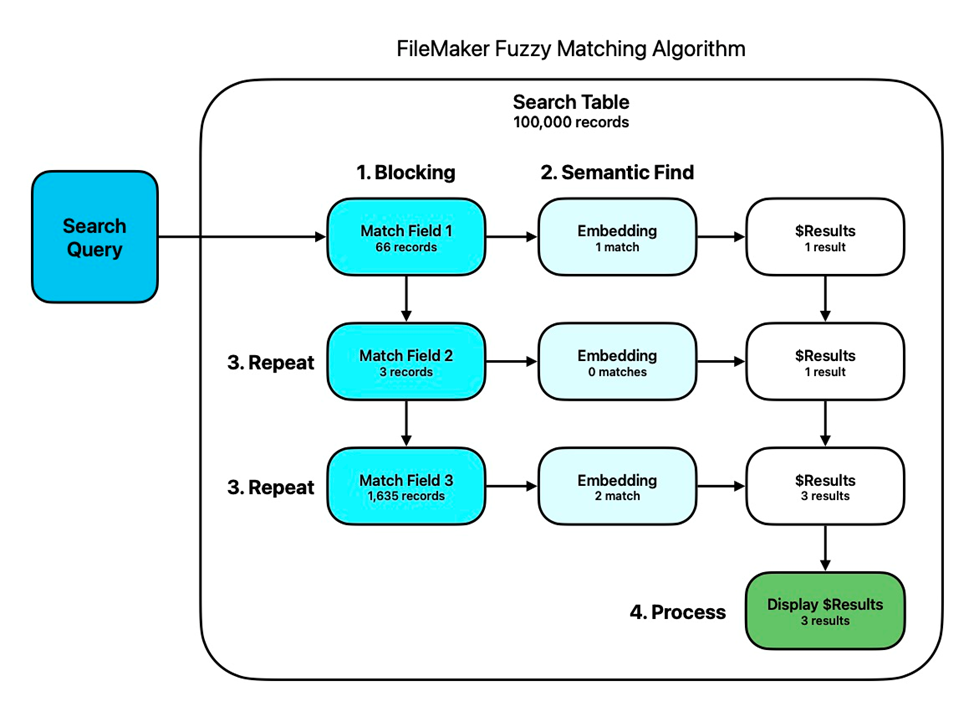
Once you’ve chosen your match field(s) and created vector embeddings of them, the process for entity matching using Semantic Find goes like this:
- Blocking – Perform a standard FileMaker find on a single match field to create a subset of records that has a greater likelihood of containing the match you’re looking for.
- Semantic Find – Perform Semantic Find on this subset of records, collecting any matches in a variable.
- Repeat – Loop back over steps 1-2 several more times, blocking on a different match field each time, and appending the new results (skipping any records that come up again).
- Process Results – Take the results and process them how you see fit.
This process should yield one or more records that were exactly matched to a portion of the search query, but fuzzy matched to the rest of the search query. Ideally, one of them has a high enough match score that you can safely call it a match!
Step 1 – Blocking
Because semantic find performance can be slow against large data sets, it’s generally necessary to reduce the size of your initial found set. This is called blocking, and it aims to pare down the number of records to search in order to find what we’re looking for:
Blocking is the first step in entity resolution that groups similar records together based on certain attributes. By doing so, the process narrows its search to only consider comparisons within each block, rather than examining all possible record pairs in the dataset. This significantly reduces the number of comparisons and accelerates the ER process. As it skips many comparisons, it possibly leads to missed true matches. Therefore, Blocking should achieve a good balance between efficiency and accuracy. (Tomonori Masui, Sept 21, 2023 – Towards Data Science) It takes significantly less time to perform a semantic find against 1,000 records than it does against 100,000 records, so this process is essential
It takes significantly less time to perform a semantic find against 1,000 records than it does against 100,000 records, so this process is essential.
Start by identifying some method to eliminate the largest number of records from your initial found set. The biggest tradeoff between efficiency and accuracy may be in how you decide to do this. The idea is to get a smaller set of records that have a higher likelihood of containing the match you’re looking for, in which we can search further using Semantic Find. Some examples:
- If you’re looking in a Contacts table, and you know that the contact you’re looking for is in the “Billing” category, then start by reducing your found set to just those records that are type “Billing”.
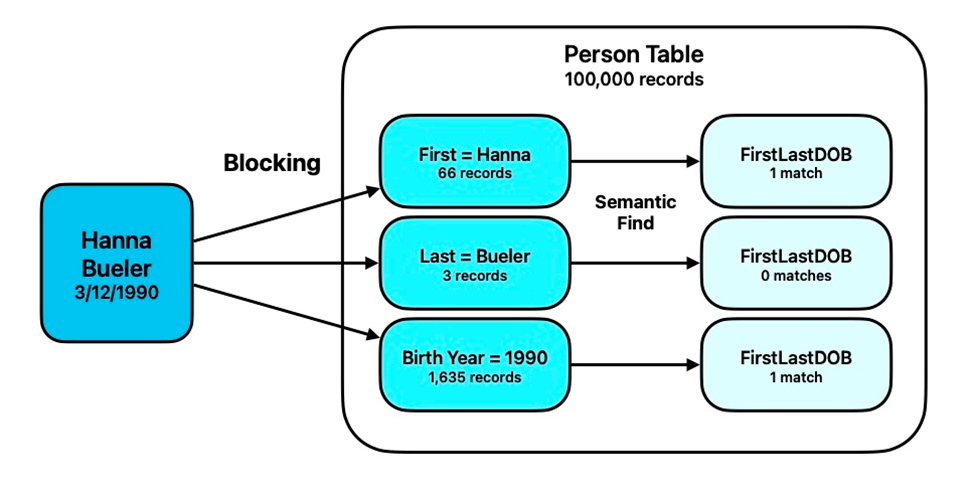
- If you’re trying to find a duplicate person named “Hanna Beuler”, try reducing your found set to all records with first name “Hanna”; the second time around you might search for all records that have a last name “Beuler”; A third round could narrow the set to people born in 1990.
- Searching in an Organizations table, you could narrow your first round of blocking by City, the second by Postal Code, and a third by OrganizationType.
Step 2 – Perform semantic find(s) on each blocking set
This step is pretty straightforward — in each found set that results from a blocking step, perform a semantic find on your embedding field. Since you want to compare your start text with the embedding field, you need to create an embedding on the fly of your starting text. In our “Hanna Beuler” example, the embeddings in our large table of 100k Person records are created from a concatenated field that consists of First Name, Middle Initial, Last Name, and Date of Birth (in ISO format) that looks like this:
Hannah C Bueler 1990-12-03
When we begin our semantic find, we’ll need to take our search string “Hanna Beuler, 3/12/1990”, and create an embedding out of it using the exact same format we used for our embedding fields, so it looks like this:
Hanna Beuler 1990-03-12
The embedding must also be created using the same model you used to create all of the embeddings in your search table. Use the ‘Insert Embedding’ script step on this single search string, and instead of storing it in a container field in a table, you’ll store this embedding in a global container field:
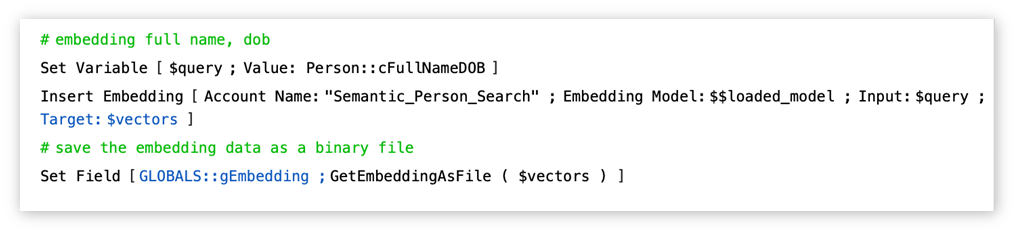
…and then use that global field in the semantic find as the ‘Vector’ parameter in the ‘Perform Semantic Find’ script step:

The recommended settings for the ‘Perform Semantic Find’ step are as follows:
Query by: Vector Data
Vector: [your global embedding field] //this is the search query
Record Set: Current Found Set //this is the set of records reduced by blocking
Target field: [your embedding field] //this is where your embeddings are stored
Return count: 10 //this may vary, but keep it relatively small
Cosine similarity condition: greater than
Cosine similarity value: .85 //my tests indicate that < 85% match is not very good
Save result: $result_variable //store results in a variableStep 3 – Repeat blocking process
Now that you’ve searched a single match field for an exact match, performed a semantic find within this found set on the embedded field and stored the results in a variable, repeat this process with a NEW match field. Each time we come up with a reduced found set, we perform a semantic find on this found set, using the same global embedding field, and append the new results to our $Results variable (skipping over any duplicates).
Our hope is that out of these multiple searches (none of which on their own would yield a strong match), at least one of the found sets will contain a partial match to the actual “Hannah C Bueler” record, which we can then match to using Semantic Find.
If, after this process, we still haven’t found any close matches, we may assume that either a) any duplicate records are perhaps too different to easily locate, or b) there are no duplicates to be found.
Step 4 – Process the results of the semantic find
At this point, the process should leave us with a JSON variable containing an array of matches that look something like this:
[
{"recordId":"99920","similarity":0.988967784539129},
{"recordId":"87405","similarity":0.829515648500795},
{"recordId":"49850","similarity":0.802658597565103},
{"recordId":"45721","similarity":0.817432345089549}
]What you choose to do with these results will depend on your specific use case. Since the purpose of Entity Matching is to search for duplicates, handling them will depend on your business logic. The cosine similarity score tells you how close the vector embeddings were to each other, and gives a good indication of whether you have a likely match. While all Large Language Models will have some variation, of the ones I’ve tested that return the best results (Gemini “text-embedding-004”, OpenAI “text-embedding-3-small”, and JinaAI “jina-embeddings-v4-vllm-text-matching”), a cosine similarity below ~85 does not seem to be useful at all for entity matching. Given this, you might consider any of the following for those matches that are greater than 0.85 similarity:
- Display the matches for the user in a virtual list.
- Create a join table that connects an initial search record to its matched records in a separate table.
- Immediately merge duplicate records that have a high enough similarity score.
- Automatically create a new record if no high matches are returned.
- Flag records for a manual review later.
What I did (my proof-of-concept)
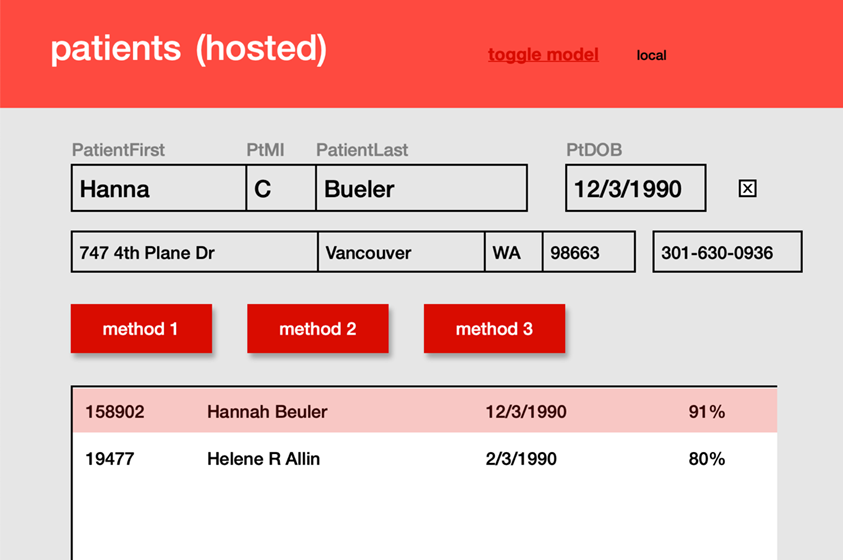
I built and tested an entity matching proof-of-concept in Claris FileMaker 22 to find Persons in a database of ~102k records. The idea is based on a use case in which incoming laboratory results, which contain patient information, need to be matched against a large table of existing Person records for public health investigation.
Environment
The test file has four tables:
- Patient – holds our input data
- Person – the full set of Person records to search against
- Embeddings – contains vector embeddings of Person records
- SearchJoin – a join table to connect the results of our search with the input record
There are also a couple of global fields that are in their own table, but they could be located anywhere.
The file is hosted on a FM Server version 22.0.1, which has recently been optimized specifically for performing semantic find on the server. I tried this on earlier server versions and performance was not good, so it’s recommended that you use the latest version of FileMaker server to take advantage of the recent improvements to semantic find. Offloading your searches to the server using PSoS is highly recommended. A typical search using the techniques described here typically takes only a few seconds, but with various adjustments to blocking and server conditions, this could vary.
Starting with a single person record as the ‘input’ (the Patient record), I search the Person table to locate a likely match. I begin by blocking against four different fields (First Name, Last Name, Date of Birth, and Phone number), and run the semantic find on each smaller found set using an embedding of the combined Full Name and Date of Birth. This yields quite good results, and can even identify likely matches when all three data points (First, Last, DOB) are slightly different! With slight variations in only one or two of these points, performance is remarkable.
When a list of matches is returned that are higher than 85% similarity, I create records in a join table that displays the matching records are their scores for the user. At this point they might choose to merge the two records, or delete one and keep the other.
Conclusion
The Semantic Find features in FileMaker 22, when used as described here, can yield excellent results when used for entity matching as a first step in a data deduplication process. Hopefully, this gives you a starting point to deploy your own “Fuzzy Matching” module in your FileMaker systems along the path to solving tough entity matching issues. It can prove to be a true game changer.