
With the long list of new features being released in FileMaker Pro 17, one item that piqued the interest of my inner geek was this new function: Get(UUIDNumber). This new function is useful because now you can store your UUIDs in a Number data-typed field instead of having to use a Text data-typed field. My hypothesis is that storing Numbers in the database will take up less space in the file. (I’m not sure where I got that notion, but it’s stuck with me for a while now…perhaps it was the Tech specs from an older version, where it described the minimum size needed to store numbers vs. text.)
Get(UUIDNumber)
This Get(UUIDNumber) function returns a unique, 24-byte (192-bit) number. For example, you can use this function to generate a unique ID of a record. Using this function instead of Get(UUID) as the calculated value of a primary key field may improve the performance of operations based on relationships.
FM Help (source)
The document states that the result is a specific size, but during my testing I found that the length of the returned UUID was slightly variable – I got both 57 digit and 58 digit results. (That was as reported by my Data Viewer, using the calculation “Length (Get(UUIDNumber))” – I didn’t take the time to actually count the digits.)
There might be some other performance improvements with this new function – maybe the speed of function/calculation itself is faster? Or, as the help states, it may lead to improvements in Relationship speeds. I didn’t test for relationship speed improvements, but I will address storage size and function speed.
The tested: I started with a new blank file created in FileMaker Pro Advanced 17: 1 table, 1 new field, and removed all of the default fields. (Default Fields are a new feature in 17, too.) I wrote a script to create 1,000,000 new records. For each test condition I started with a Clone of the starting file, just so that there wouldn’t be any cruft in the file structure itself. The layout that I used to run this script from had no fields on it at all – just the button to launch the script. Script Workspace and Data Viewer were (usually) closed during these tests.
To calculate the final file size I simply used the “Size” (not the “on disk”) reported by macOS Finder’s ‘GetInfo’ function on the file, after I had closed the file. The timing information came from steps in the script itself, using get ( CurrentTimeUTCMilliseconds ). These tests were done on a local offline file, running on a fairly recent computer: MacBook Pro 13, 2017; 3.1 GHz Intel Core i5 CPU; SSD drive.
As a side experiment I took this opportunity to test some perceptions that I had regarding certain script steps. So I did a number of different variations of this test to see how other parts of the system performed under different circumstances: some used an auto-enter calculation in the field definition to populate the UUID, some used a discrete Set Field script step, some used different constructs in the script to perform the loop, etc. I didn’t summarize that data out of the overall results, but the numbers are there in the chart.
Here are the measurements:
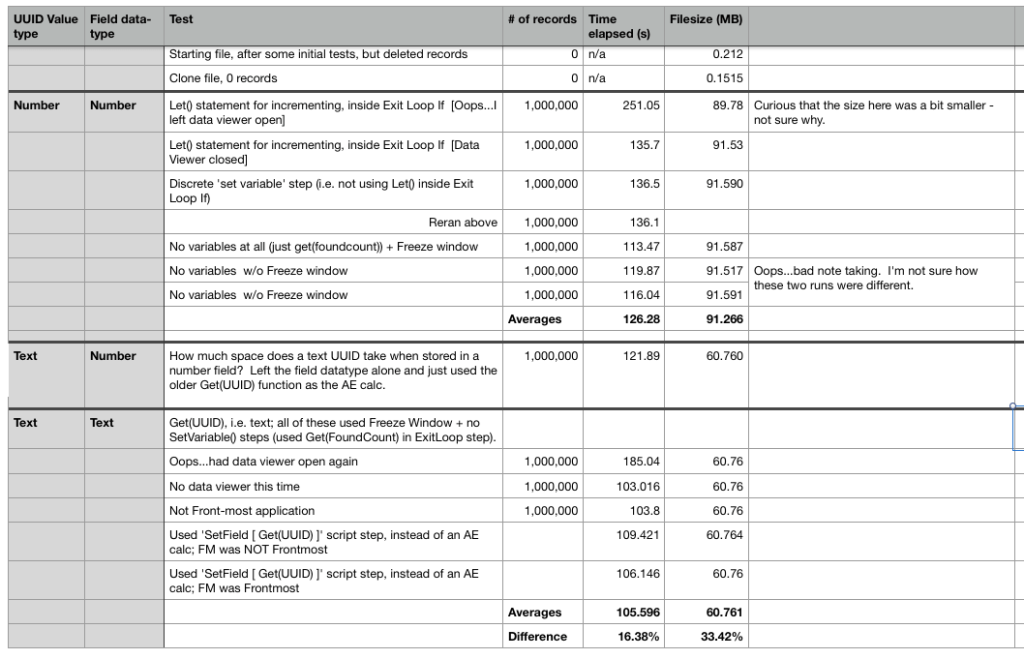
Picking out the results:
| AVG Time | AVG Size | |
| Get(UUIDNumber) | 126.3 | 91.27MB |
| Get(UUID) | 105.6 | 60.76MB |
I was surprised at the results: that’s ~33% smaller is size and ~16% faster for the older text-based UUID function!
Why the larger size for the new Get(UUIDNumber)? From the Help on 17 for the original text-based Get(UUID) function:
Returns a unique 16-byte (128-bit) string…
This results in a 36 character value, including the dashes. This compares to the new number version’s length of 24-byte/192-bit string (57 or 58 characters). That in itself is 37% smaller; very similar to the 33% difference I found in file sizes. The new number version needs to be longer than the Text version in order to still provide the same (or better) guarantees of uniqueness. (The Help article didn’t describe the probability of returning the same value twice using the new function.)
I was surprised by these results, initially, because I was expecting the Text data-type fields to take up more space. I hadn’t considered the actual length of the strings involved, before running these tests. The new Get(UUIDNumber) function has significantly more characters than the Text version, so it ends up taking up more space in your database.
As for the difference in speeds of the two functions, that is something that I imagine the FileMaker engineers would be able to improve upon. Not that it is terribly slow, by any means. On average it took about 0.000117 seconds to create each record, which includes the generation of the UUID number and committing it.
Therefore, the original text-based UUID ends up being better in all respects – space taken up by the database to store the data, and the speed required to generate that data. I’m not sure that there’s much to recommend the new function – EXCEPT that FileMaker, Inc. are dangling out that possibility of improved relationship speeds. Now THAT might be worth the price of storing longer numeric values.
Update Since Publication
I ran a couple more tests to fully explore my misconception about Number fields taking up less space than Text fields.
For one follow-up test I used a fixed length string in each field type: “1234567890” in a Text-typed field, the number 1234567890 in a Number-typed field. I used 1,000,000 records again. Care to guess which one was bigger? Neither one – they were essentially exactly the same size at 25.985MB. They also took almost exactly the same amount of time to run, at 104s.
I then ran another test with just a single digit being stored, like you would for storing boolean data. For 1 million records storing either the digit 1 as a numeric data-type, or the text “1”as a Text data-type, the two files ended up being identical in size. I think that I can now officially disabuse myself of the notion that Number fields can be smaller than Text fields.
But with all that said and done, there are still differences you need to consider when picking your field data-types. Indexing behaves rather differently between the two types – that will affect the overall storage size of the file. I will have to test the effects of that in future experiments. And again, the hinted at possible performance improvements could easily be the deciding factor in what you choose, instead of storage size or speed of calculation.
If you have questions about the content in this article, feel free to contact us!
*This article was originally written for AppWorks, which has since joined Direct Impact Solutions. This article is intended for informative purposes only. To the best of our knowledge, this information is accurate as of the date of publication.